


前言:在开发过程中没有太多存在感的DNS,其实就很符合“透明多级分流”的特点。
优化传输链路的前端设计原则
本节前言:随着HTTP协议的发展,从上世纪90年代的HTTP1.0和HTTP1.1,到2015年发布的HTTP2,再到2019年发布的HTTP3,
适合HTTP传输的请求的特征也在不断变化,未来,以下这些以优化传输链路为目的的前端设计原则,或许会成为奇技淫巧,甚至成为反模式,不再适用。
这些设计原则主要有:
Minimize HTTP Requests
即减少请求数量:对于客户端发出的请求,服务器每次都需要建立通信链路进行数据传输,这些开销很昂贵,所以减少请求的数量,就可以有效地提高访问性能。例如,有如下前端手段:
a. 雪碧图(CSS Sprites)
b. CSS、JS 文件合并 / 内联(Concatenation / Inline)
c. 分段文档(Multipart Document)
d. 媒体(图片、音频)内联(Data Base64 URI)
e. 合并 Ajax 请求(Batch Ajax Request)
f. ……
Split Components Across Domains
即扩大并发请求数,现代浏览器(Chrome、Firefox)一般可以为每个域名支持 6 个(IE 为 8-13 个)并发请求。如果你希望更快地加载大量图片或其他资源,就需要进行域名分片(Domain Sharding),将图片同步到不同主机或者同一个主机的不同域名上。
GZip Components
即启用压缩传输:启用压缩能够大幅度减少需要在网络上传输内容的大小,节省网络流量。
Avoid Redirects
即避免页面重定向:当页面发生了重定向,就会延迟整个文档的传输。在 HTML 文档到达之前,页面中不会呈现任何东西,会降低用户的体验。
Put Stylesheets at the Top,Put Scripts at the Bottom
即按重要性调节资源优先级:将重要的、马上就要使用的、对客户端展示影响大的资源,放在 HTML 的头部,以便优先下载。
适合HTTP传输的请求的特征变化
上文提到的,随着HTTP协议的变化,适合HTTP传输的请求的特征也在变化,主要是指:
连接数优化
HTTP(特指 HTTP/3 以前)是以 TCP 为传输层的应用层协议,但 HTTP over TCP 这种搭配,只能说是 TCP 目前在互联网中的统治性地位所造就的结果,而不能说它们两者配合工作就是合适的。
HTTP与TCP搭配的不合适,要从两者的特征、使用场景入手来分析:HTTP传输对象的主要特征是数量多、时间短、资源小、切换快;而TCP传输的主要特征是基于三次握手的高开销(百毫秒级,慢启动特性,刚建立连接时传输速度最低,后面逐步加速至稳定),面向长时间,大数据传输,它只要在较长一段时间尺度内,才能展现出稳定性和可靠性的优势,不会因为建立连接成本高昂,成为使用瓶颈。
因此,HTTP over TCP这种搭配在目标特征上是有矛盾的,以至于HTTP/1.x时代,大量短而小的TCP连接导致了网络性能的瓶颈。
一旦需要使用者(开发者)需要通过各种上述Tricks,来解决基于技术根基而出现的各种问题时,往往会陷入“两害相权取其轻”的困境,这意味着,它们只能是Tricks,而无法成为一种标准的设计模式。
连接复用技术的优势和缺陷
原理
持久连接(Persistent Connection),或者叫连接Keep-Alive 机制的原理:让客户端对同一个域名长期持有一个或多个不会用完即断的 TCP 连接。典型做法是在客户端维护一个 FIFO 队列,每次取完数据之后的一段时间内,不自动断开连接,以便获取下一个资源时可以直接复用,避免创建 TCP 连接的成本。
副作用
连接复用技术依然是不完美的,最明显的副作用就是“队首阻塞”(Head-of-Line Blocking)问题。
比如,浏览器有 10 个资源需要从服务器中获取,这个时候它把 10 个资源放入队列,入列顺序只能是按照浏览器预见这些资源的先后顺序来决定。但是,如果这 10 个资源中的第 1 个就让服务器陷入了长时间运算状态,而在运算结果出来之前,TCP 连接中并没有任何数据返回,此时后面的 9 个资源都必须阻塞等待。
而且,这些请求无法并行处理,因为只使用一个 TCP 连接来传输多个资源的话,一旦顺序乱了,客户端就很难区分清楚哪个数据包归属哪个资源了。
在2014年 IETF 发布的RFC 7230中,提出了名为“HTTP 管道”(HTTP Pipelining)复用技术,试图在 HTTP 服务器中也建立类似客户端的 FIFO 队列,让客户端一次性将所有要请求的资源名单全部发给服务端,由服务端来安排返回顺序,但其实也无法根本解决问题,因为服务端也无法精确计算每项操作的耗时。
连接复用技术解决方案
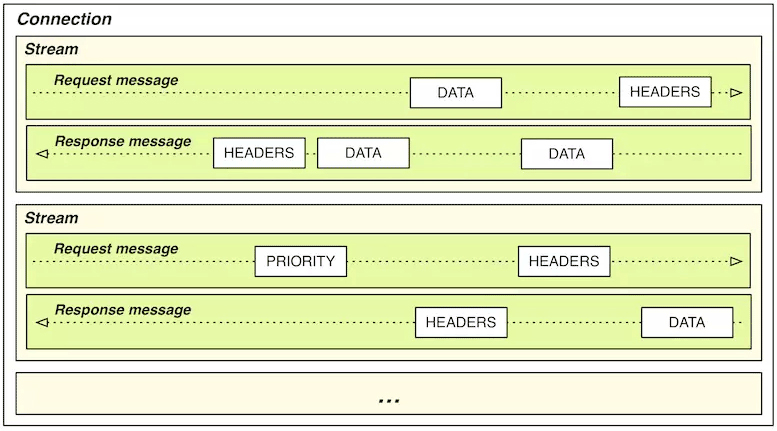
HTTP/2多路复用技术:在 HTTP/1.x 中,HTTP请求就是传输过程中最小粒度的信息单位;而在 HTTP/2 中,帧(Frame)才是最小粒度的信息单位,它可以用来描述各种数据,比如请求的 Headers、Body,或者是用来做控制标识,如打开流、关闭流。
这里的流(Stream),是一个逻辑上的数据通道概念,每个帧都附带有一个流 ID,以标识这个帧属于哪个流。这样在同一个 TCP 连接中,传输的多个数据帧就可以根据流 ID 轻易区分出来。
优势
- HTTP/2 可以对每个域名只维持一个 TCP 连接(One Connection Per Origin),来以任意顺序传输任意数量的资源。既减轻了服务器的连接压力,也使开发者不用通过域名分片来突破浏览器对每个域名最多 6 个连接数的限制。
- 没有了TCP连接数的压力,客户端就不需要再刻意压缩 HTTP 请求了,所有通过合并、内联文件(无论是图片、样式、脚本)以减少请求数的需求都不再成立,甚至反而是徒增副作用的反模式。
对压缩/合并请求等行为的影响
- 在 HTTP/2 中,Header 压缩的原理是基于字典编码的信息复用,简而言之是同一个连接上产生的请求和响应越多,动态字典积累得越全,头部压缩效果也就越好。所以,
HTTP/2 是单域名单连接的机制,合并资源和域名分片反而对性能提升不利。 - 与 HTTP/1.x 相反,HTTP/2 本身反而变得更适合传输小资源了,比如传输 1000 张 10K 的小图,HTTP/2 要比 HTTP/1.x 快,但传输 10 张 1000K 的大图,则应该 HTTP/1.x 会更快,这是由于TCP可靠传输机制导致的(一个TCP包错误,会导致所有的流都要等待包重传成功),因次把小文件合并成大文件在HTTP/2下没有好处。
传输压缩
如何判断HTTP请求中的资源已经传输完毕?
- 可以通过TCP连接断开来标识。(但TCP连接成本高,不能轻易断开)
- 持久连接机制中,不再通过TCP断开为唯一标识,而是通过压缩后的Header参数Content-Length来判断。
内容压缩与持久连接机制的冲突
压缩与节约TCP连接的持久连接机制,是存在冲突的。
HTTP就支持GZip压缩,而且启用了静态预压缩,在传输之前就把文件压缩成.gz,可以通过请求header的Content-Length来标识资源传输完毕,而现在Web服务器不需要通过预压缩方式,而是对符合压缩条件的请求,在即将输出时,在内存数据流中进行即时压缩,,不必等全部压缩完再返回,可以显著提高“首字节时间”,这导致服务器无法给出Content-Length这个响应Header,因为输出Header时,它还不知道压缩后资源的确切大小。
因此,在HTTP/1.0中,持久连接和即时压缩只能二选一。
冲突的解决
HTTP/1.1 版本中增加了另一种“分块传输编码”(Chunked Transfer Encoding)的资源结束判断机制,彻底解决了 Content-Length 与持久连接的冲突问题。
原理为:在响应 Header 中加入“Transfer-Encoding: chunked”,代表这个响应报文将采用分块编码。此时,报文中的 Body 需要改为用一系列“分块”来传输。每个分块包含十六进制的长度值和对应长度的数据内容,长度值独占一行,数据从下一行开始。最后以一个长度值为 0 的分块,来表示资源结束。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
HTTP/1.1 200 OK
Date: Sat, 11 Apr 2020 04:44:00 GMT
Transfer-Encoding: chunked
Connection: keep-alive
25
This is the data in the first chunk
1C
and this is the second one
3
con
8
sequence
0
根据分块长度,可知前两个分块包含显式的回车换行符(CRLF,即\r\n 字符)
1
2
3
4
"This is the data in the first chunk\r\n" (37 字符 => 十六进制: 0x25)
"and this is the second one\r\n" (28 字符 => 十六进制: 0x1C)
"con" (3 字符 => 十六进制: 0x03)
"sequence" (8 字符 => 十六进制: 0x08)
解码后,内容为:
1
2
3
This is the data in the first chunk
and this is the second one
consequence
HTTP/1.1 通过
分块传输解决了即时压缩与持久连接并存的问题,到了 HTTP/2,由于多路复用和单域名单连接的设计,已经不需要再刻意去强调持久连接机制了,但数据压缩仍然有节约传输带宽的重要价值。
快速UDP网络连接
为什么HTTP/3将基于UDP协议?
HTTP 是应用层协议,而不是传输层协议,它的设计原本并不应该过多地考虑底层的传输细节。从职责上来讲,(HTTP/1/1.1/2.0分别提供的)持久连接、多路复用、分块编码这些能力,已经或多或少超过了应用层的范畴。
所以,要想从根本上改进 HTTP,就必须直接替换掉 HTTP over TCP 的根基,即 TCP 传输协议,这便是最新一代 HTTP/3 协议的设计重点
什么时QUIC?
2013 年,Google 在它的服务器(如 Google.com、YouTube.com 等)及 Chrome 浏览器上,同时启用了名为“快速 UDP 网络连接”(Quick UDP Internet Connections,QUIC)的全新传输协议, 2015 年,Google 将 QUIC 提交给了 IETF,并在 IETF 的推动下,对 QUIC 进行重新规范化(为以示区别,业界习惯将此前的版本称为 gQUIC,规范化后的版本称为 iQUIC)。2018 年末,IETF 正式批准了 HTTP over QUIC 使用 HTTP/3 的版本号,将其确立为最新一代的互联网标准。
QUIC对比TCP的问题与解决方案?
UDP 协议没有丢包自动重传的特性,因此 QUIC 的可靠传输能力并不是由底层协议提供的,而是完全由自己来实现。
由 QUIC 自己实现的好处是能对每个流能做单独的控制,如果在一个流中发生错误,协议栈仍然可以独立地继续为其他流提供服务。
QUIC对移动设备的支持
QUIC 的另一个设计目标是面向移动设备的专门支持。
以前 TCP、UDP 传输协议在设计的时候,根本不可能设想到今天移动设备盛行的场景,因此肯定不会有任何专门的支持。而QUIC 在移动设备上的优势就体现在网络切换时的响应速度上。
QUIC 提出了连接标识符的概念,该标识符可以唯一地标识客户端与服务器之间的连接,而无需依靠 IP 地址。这样,在切换网络后,只需向服务端发送一个包含此标识符的数据包,就可以重用既有的连接。
解惑:HTTP/2传输大文件为什么慢?
因为TCP的可靠传输特性,当HTTP over TCP时,若传输大文件,在大多数情况下,TCP 协议接到数据包丢失或损坏通知之前,可能已经收到了大量的正确数据,但是在纠正错误之前,其他的正常请求都会等待甚至被重发。