


并发编程的源头
现代计算机体系中,随着CPU、内存、I/O 设备快速迭代,有一个核心矛盾一直存在,就是这三者的速度差异。
根据木桶理论,程序整体的性能取决于最慢的操作——读写 I/O 设备,也就是说单方面提高 CPU 性能是无效的。为了合理利用 CPU 的高性能,平衡这三者的速度差异,计算机体系结构、操作系统、编译程序都做出了贡献,主要体现为:
- CPU:增加缓存,均衡与内存的速度差异
- 操作系统:增加了进程、线程,以分时复用 CPU,进而均衡 CPU 与 I/O 设备的速度差异
- 编译程序:优化指令执行次序,使得缓存能够得到更加合理地利用。
但天下没有免费的午餐,有了以上三种优化,同时也引入了三类问题:【缓存】导致的【可见性】问题;【线程切换】导致的【原子性】问题 ;【指令优化】导致的【有序性】问题。
这三类问题,就是并发编程需要面对各种问题的根源。
源头1:缓存导致的可见性问题
一个线程对共享变量的修改,另外一个线程能够立刻看到,我们称为可见性
单核时代,所有的线程都是在一颗 CPU 上执行,CPU 缓存与内存的数据一致性容易解决。因为所有线程都是操作同一个 CPU 的缓存,一个线程对缓存的写,对另外一个线程来说一定是可见的。
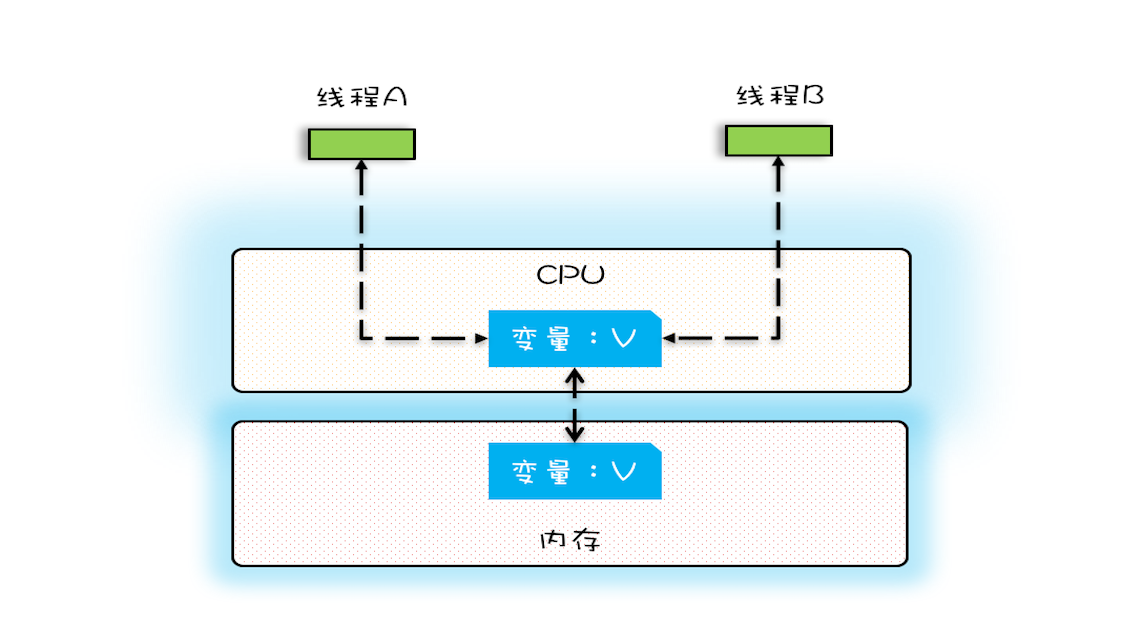
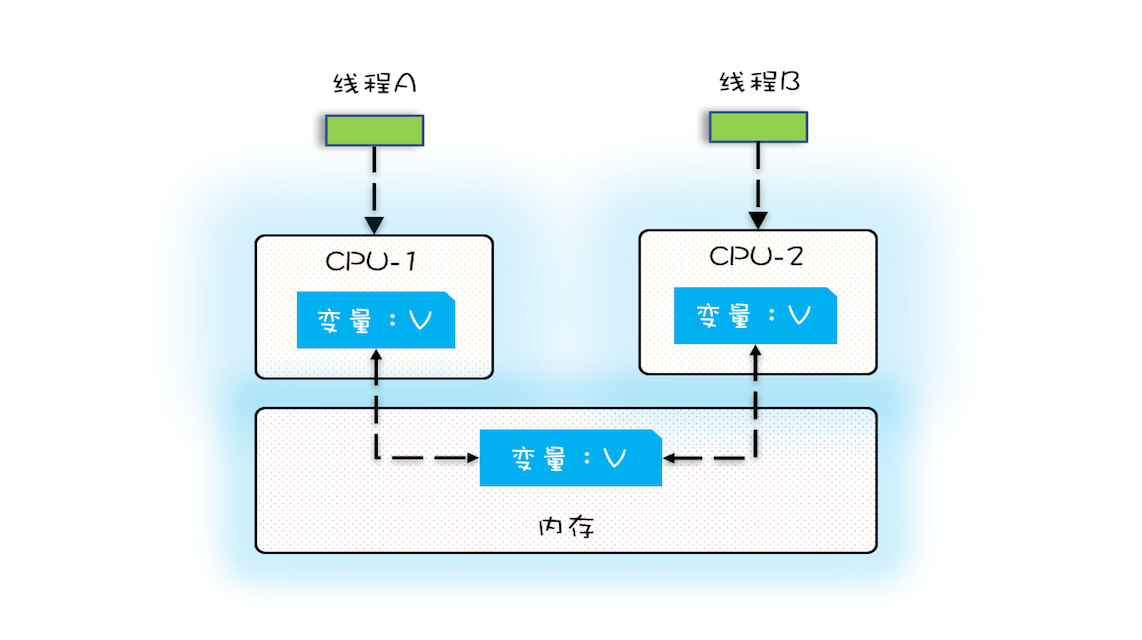
多核时代,每颗 CPU 都有自己的缓存,这时 CPU 缓存与内存的数据一致性就没那么容易解决了,当多个线程在不同的 CPU 上执行时,这些线程操作的是不同的 CPU 缓存。
源头2:线程切换带来的原子性问题
我们把一个或者多个操作在 CPU 执行的过程中不被中断的特性称为原子性。
由于 IO 太慢,早期的操作系统就发明了多进程,操作系统允许某个进程执行一小段时间,过了这段时间操作系统就会重新选择一个进程来执行,我们称为“任务切换”,这段时间称为“时间片”。
在一个时间片内,如果一个进程进行一个 IO 操作,例如读个文件,这个时候该进程可以把自己标记为“休眠状态”并出让 CPU 的使用权,待文件读进内存,操作系统会把这个休眠的进程唤醒,唤醒后的进程就有机会重新获得 CPU 的使用权了。这就是多进程分时复用的好处。
早期操作系统调度CPU都是基于进程切换的,但是进程不共享内存空间,切换时需要切换内存映射地址,成本较高;现代操作系统,都是基于更轻量的线程来做CPU调度,而线程之间可以共享内存。
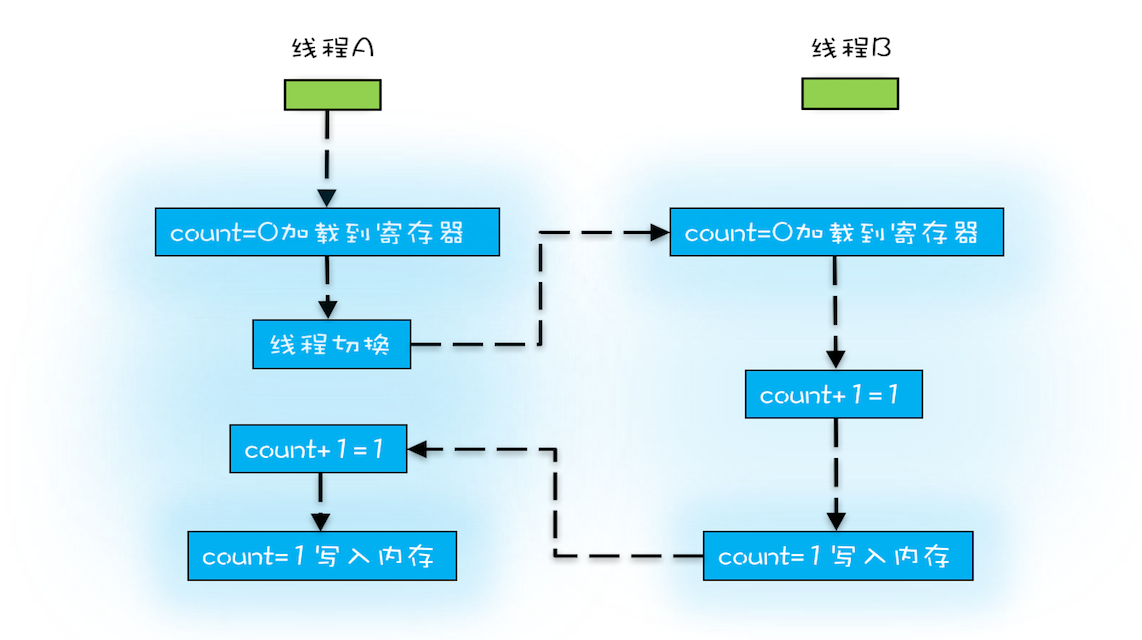
任务切换,多发生在时间片结束时,而现代高级编程语言中的一条指令,往往对应多条CPU指令,比如i++,分为三个CPU指令:
- 指令 1:首先,需要把变量 count 从内存加载到 CPU 的寄存器;
- 指令 2:之后,在寄存器中执行 +1 操作;
- 指令 3:最后,将结果写入内存(缓存机制导致可能写入的是 CPU 缓存而不是内存)。
操作系统任务切换,可以发生在任何一条CPU指令完成后,就会带来原子性问题。
源头3:编译优化带来的原子性问题
有序性指的是程序按照代码的先后顺序执行。
编译器为了优化性能,有时候会改变程序中语句的先后顺序,例如程序中:“a=6;b=7;”编译器优化后可能变成“b=7;a=6;”,在这个例子中,编译器调整了语句的顺序,但是不影响程序的最终结果。
JMM如何解决并发三大问题
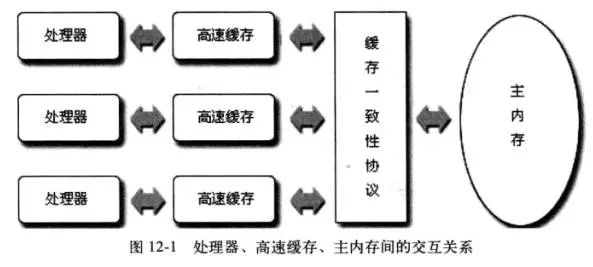
JMM内存模型与硬件结构关系:
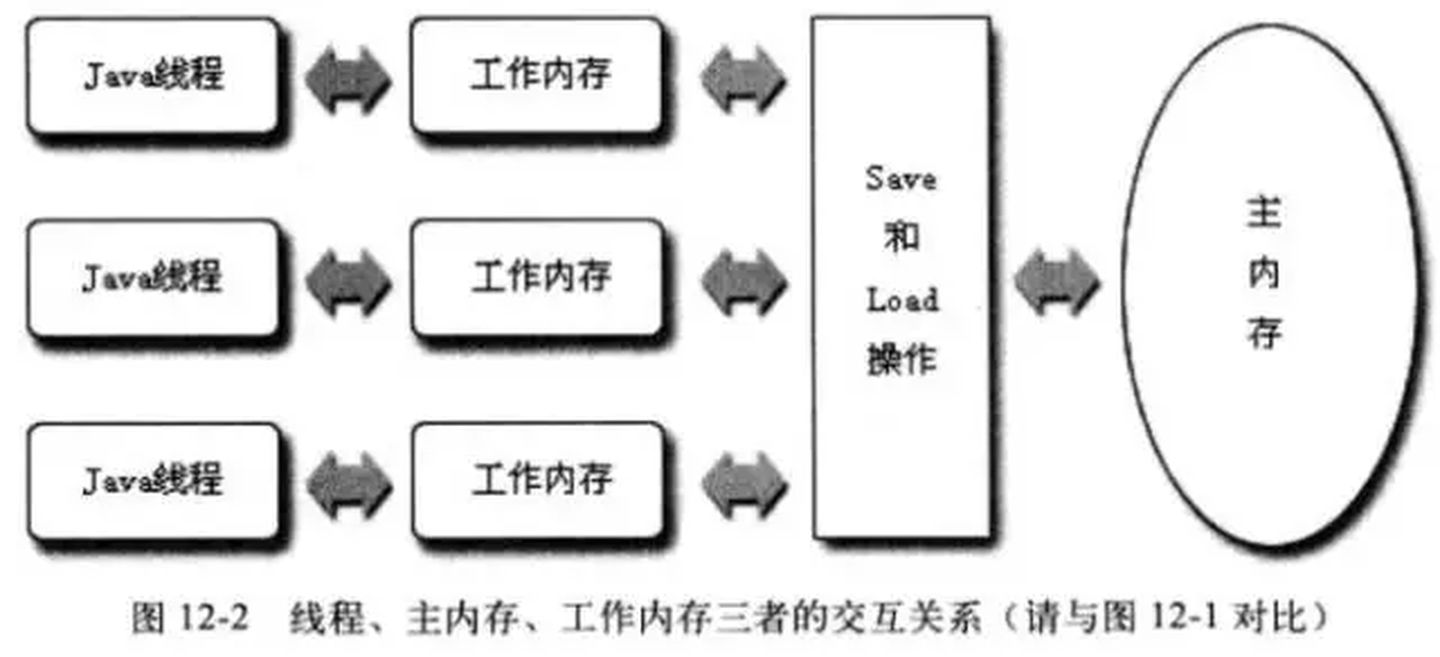
JMM如何解决可见性与有序性?
导致可见性的原因是缓存,导致有序性的原因是编译优化,那解决可见性、有序性最直接的办法就是禁用缓存和编译优化,但是这样问题虽然解决了,我们程序的性能可就堪忧了。因此,合理的方案应该是按需禁用缓存以及编译优化。
Java内存模型就给出了一系列原则,规范了JVM如何提供按需禁用缓存和编译优化的方法。具体来说,这些方法包括volatile、synchronized和final关键字,以及六项Happens-Before规则。
volatile的基础语义
我们声明一个 volatile 变量 volatile int x = 0,它表达的是:告诉编译器,对这个变量的读写,不能使用 CPU 缓存,必须从内存中读取或者写入。
观察如下代码,当线程A先执行writer()方法,线程B后执行reader()方法时,B读取到的x值是多少?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// 以下代码来源于【参考1】
class VolatileExample {
int x = 0;
volatile boolean v = false;
public void writer() {
x = 42;
v = true;
}
public void reader() {
if (v == true) {
// 这里x会是多少呢?
}
}
}
结果:在JDK1.5之前,x为0,JDK1.5之后,x为42。
原因:x是一个共享变量,若线程A、B是不同的CPU线程,对应不同的CPU缓存,当线程A更新x的值后,可能并未更新至主内存,导致线程B的working memory中(即CPU缓存)仍为旧值0
那么JDK1.5是如何解决这个问题的?
JDK1.5,对volatile语义进行了一次极大的增强,使得被volatile修饰的变量前修改的值,可以被读取volatile变量时读取。
增强方式,是添加了一条Happens-Before原则。
Happens-Before原则解析
如何理解 Happens-Before 呢?如果望文生义(很多网文也都爱按字面意思翻译成“先行发生”),那就南辕北辙了,Happens-Before 并不是说前面一个操作发生在后续操作的前面,它真正要表达的是:前面一个操作的结果对后续操作是可见的。
概括其作用,可以说Happens-Before原则约束了编译器的优化行为,允许编译器优化,但是要求编译器优化后,一定遵循Happens-Before原则,即完成所谓的“按需禁用缓存与编译优化”:
程序的顺序性原则
简单理解为:单线程内(重要前提),前面的操作Happens-Before于后续的任意操作:即程序前面对某个变量的修改一定是对后续操作可见的。
volatile变量原则
对一个volatile变量的写操作,Happens-Before于后续对这个变量的读操作。
注意,本身这条原则,并没有对volatile本身语义禁用缓存有什么增强,我们所说的对volatile语义做了极大扩展,需要结合下面的规则3来理解。
传递性
如果A Happens-Before B,且B Happens-Before C,那么A Happens-Before C
我们把这条原则,应用于上面的代码例子中,可以看到:
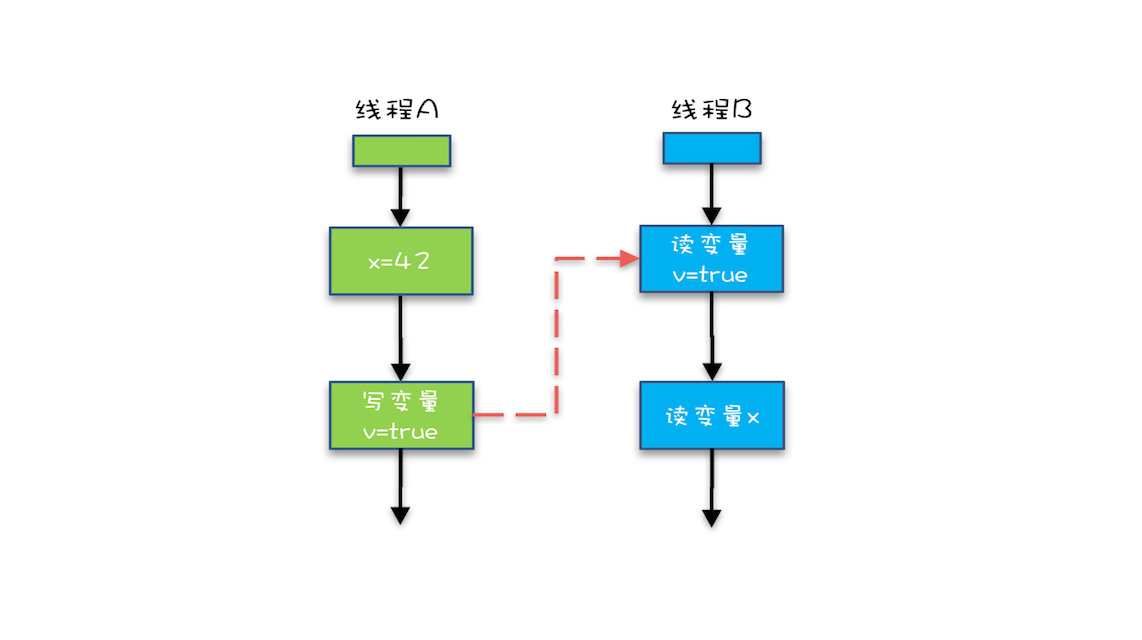
- “x=42” Happens-Before 写变量 “v=true” ,这是规则 1 的内容;
- 写变量“v=true” Happens-Before 读变量 “v=true”,这是规则 2 的内容 。
- 再根据传递性规则,我们得到结果:“x=42” Happens-Before 读变量“v=true”。
这意味着:如果线程 B 读到了“v=true”,那么线程 A 设置的“x=42”对线程 B 是可见的。也就是说,线程 B 能看到 “x == 42”。
因此,这相当于使得volatile前的普通变量写,对于volatile后的普通变量读可见,这是对volatile语义的重大增强。(为满足这一点,实际上需要编译器对于编译后的源码增加各种读写屏障来实现)
管程中锁的规则
对一个锁的解锁Happens-Before于后续对这个锁的加锁。
首先要了解什么是管程?
管程是一种同步原语,在Java中指的就是synchronized,即synchronized是Java对管程的实现
结合规则1、3、4,可以解释:为什么线程A加锁后,对共享变量的修改,对于线程B获取锁后,是可见的?
- 基于规则1:线程A修改数据happens before线程A解锁
- 基于规则4:线程A解锁happens before线程B加锁,
- 基于规则3于上述两点:线程A修改数据Happens-Before线程B加锁后的操作(读取共享数据)
因此,基于这几条规则,就要求JVM必须在解锁后,对于锁中修改的数据进行强制缓存刷新操作,使得其他线程可见。
线程start()规则
这条是关于线程启动的。它是指主线程 A 启动子线程 B 后,子线程 B 能够看到主线程在启动子线程 B 前的操作。
换句话说就是,如果线程 A 调用线程 B 的 start() 方法(即在线程 A 中启动线程 B),那么该 start() 操作 Happens-Before 于线程 B 中的任意操作。具体可参考下面示例代码。
1
2
3
4
5
6
7
8
9
Thread B = new Thread(()->{
// 主线程调用B.start()之前
// 所有对共享变量的修改,此处皆可见
// 此例中,var==77
});
// 此处对共享变量var修改
var = 77;
// 主线程启动子线程
B.start();
线程join()规则
这条是关于线程等待的。它是指主线程 A 等待子线程 B 完成(主线程 A 通过调用子线程 B 的 join() 方法实现),当子线程 B 完成后(主线程 A 中 join() 方法返回),主线程能够看到子线程的操作。当然所谓的“看到”,指的是对共享变量的操作。
换句话说就是,如果在线程 A 中,调用线程 B 的 join() 并成功返回,那么线程 B 中的任意操作 Happens-Before 于该 join() 操作的返回。具体可参考下面示例代码。
1
2
3
4
5
6
7
8
9
10
11
12
Thread B = new Thread(()->{
// 此处对共享变量var修改
var = 66;
});
// 例如此处对共享变量修改,
// 则这个修改结果对线程B可见
// 主线程启动子线程
B.start();
B.join()
// 子线程所有对共享变量的修改
// 在主线程调用B.join()之后皆可见
// 此例中,var==66
线程中断原则(不常用)
对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生,可以通过Thread.interrupted()方法检测到是否有中断发生。
对象终结原则(不常用)
一个对象的初始化完成(构造函数执行结束)先行发生于它的finalize()方法的开始。
容易忽视的final
前面我们讲 volatile 为的是禁用缓存以及编译优化,我们再从另外一个方面来看,有没有办法告诉编译器优化得更好一点呢?这个可以有,就是 final 关键字。
final 修饰变量时,初衷是告诉编译器:这个变量生而不变,可以可劲儿优化。Java 编译器在 1.5 以前的版本的确优化得很努力,以至于都优化错了。(后面就会正确优化了)
优化方式如下:
被final修饰的字段,一旦在构造器中完成了初始化,且构造器没有把this引用传递出去(发生this逃逸,比如被赋值给一个全局对象),那么其他线程中就能看到这个final字段的值。
JMM底层实现(重要,待进一步补充)
主要是通过内存屏障(memory barrier)禁止重排序的。
即时编译器根据具体的底层体系架构,将这些内存屏障替换成具体的 CPU 指令。
对于编译器而言,内存屏障将限制它所能做的重排序优化。
而对于处理器而言,内存屏障将会导致缓存的刷新操作。比如,对于volatile,编译器将在volatile字段的读写操作前后各插入一些内存屏障。